Overview

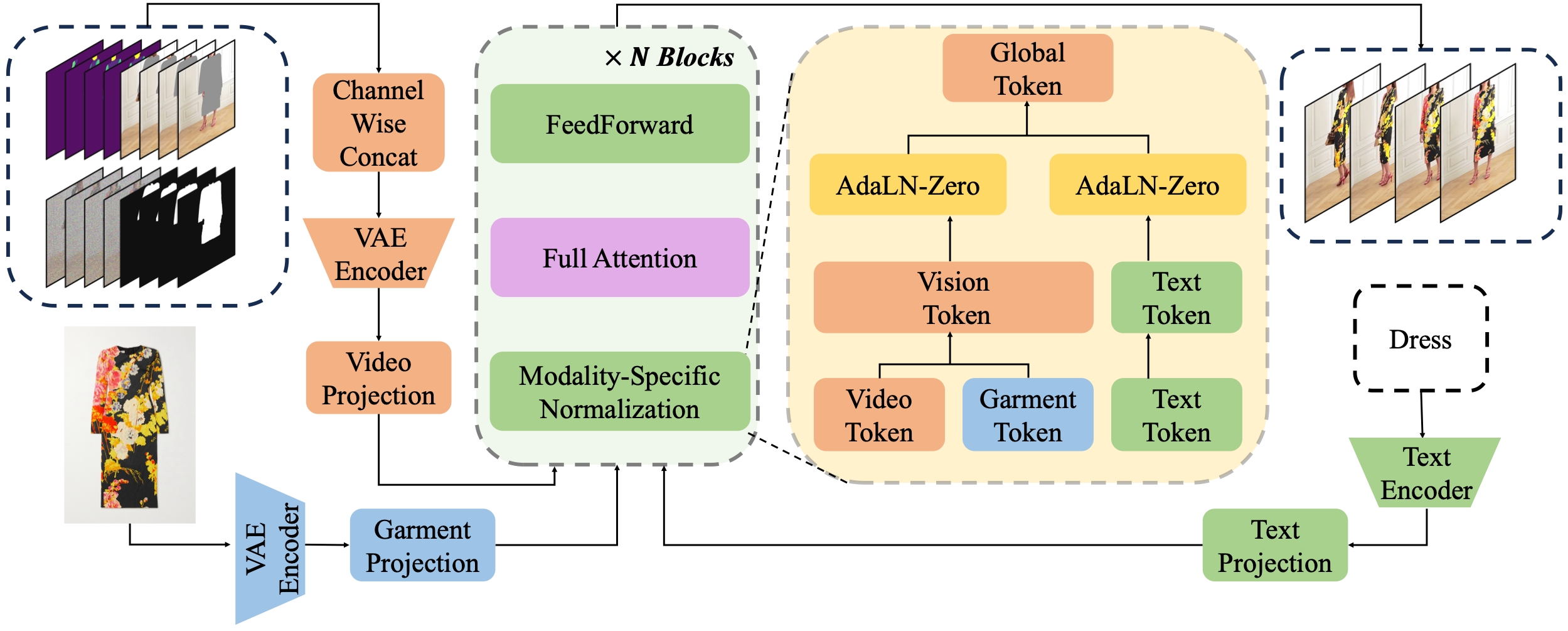
Virtual Try-On (VTON) has become a crucial tool in e-commerce, enabling the realistic simulation of garments on individuals while preserving their original appearance and pose. Early VTON methods relied on single generative networks, but challenges remain in preserving fine-grained garment details due to limitations in feature extraction and fusion. To address these issues, recent approaches have adopted a dual-network paradigm, incorporating a complementary ``ReferenceNet'' to enhance garment feature extraction and fusion. While effective, this dual-network approach introduces significant computational overhead, limiting its scalability for high-resolution and long-duration image/video VTON applications. In this paper, we challenge the dual-network paradigm by proposing a novel single-network VTON method that overcomes the limitations of existing techniques. Our method, namely MN-VTON, introduces a Modality-specific Normalization strategy that separately processes text, image and video inputs, enabling them to share the same attention layers in a VTON network. Extensive experimental results demonstrate the effectiveness of our approach, showing that it consistently achieves higher-quality, more detailed results for both image and video VTON tasks. Our results suggest that the single-network paradigm can rival the performance of dual-network approaches, offering a more efficient alternative for high-quality, scalable VTON applications.